DevOps that actually stays up—not scales in slides.
Architecture, MVP scaling, Kubernetes, cloud cost optimisation, infrastructure migration. The engineers on your kickoff call also handle your 3am page. 50+ clusters in production, four cloud providers.
- 01

Infra as actual code
Terraform. Pulumi. Helm. No clicky-clicky in cloud consoles. Your infrastructure is in git, reviewed, replayable.
- 02

Observability before launch
Metrics, logs, traces wired in week one. No production system goes live without dashboards and alerts.
- 03

Costs that go down
Average client cloud bill drops 30–40% after our optimisation pass. Right-sizing, reserved instances, spot, autoscaling.
Architecture design
From whiteboard to running cluster. Infrastructure designed for the load you have, not the one in the deck.
We design for current scale + 5x. Not 100x. Over-engineering kills startups as fast as under-engineering.
Terraform-first. Pulumi when the team prefers TypeScript. Helm charts versioned in your repo. No manual cloud-console clicks.
- 01Cloud architecture review
- 02IaC migration (Terraform / Pulumi)
- 03Network & VPC design
- 04Multi-region planning

MVP → scale
Your MVP runs on three VMs and a script. Cool. Here's how we get you to 100k users without rewriting it.
Incremental scaling. Caching first (Redis, CDN). Database read replicas next. Application sharding only when measurements demand it.
CI/CD pipelines that fail fast. Tests, lint, security scan, deploy. PR previews on every branch.
- 01Load testing & bottleneck triage
- 02Caching layers (Redis, CDN)
- 03Database scaling strategy
- 04CI/CD pipeline

Kubernetes deployments
K8s where it earns its keep. We'll tell you when ECS or Fly.io is the better call.
Kubernetes is excellent when you have polyglot workloads, complex networking, and a platform team. It's overkill when you have three microservices.
We deploy K8s clusters, write Helm charts, set up GitOps with ArgoCD or Flux. We also recommend simpler runtimes when they fit.
- 01K8s cluster setup (EKS / GKE / AKS)
- 02Helm chart authoring
- 03GitOps with ArgoCD / Flux
- 04Service mesh (when warranted)
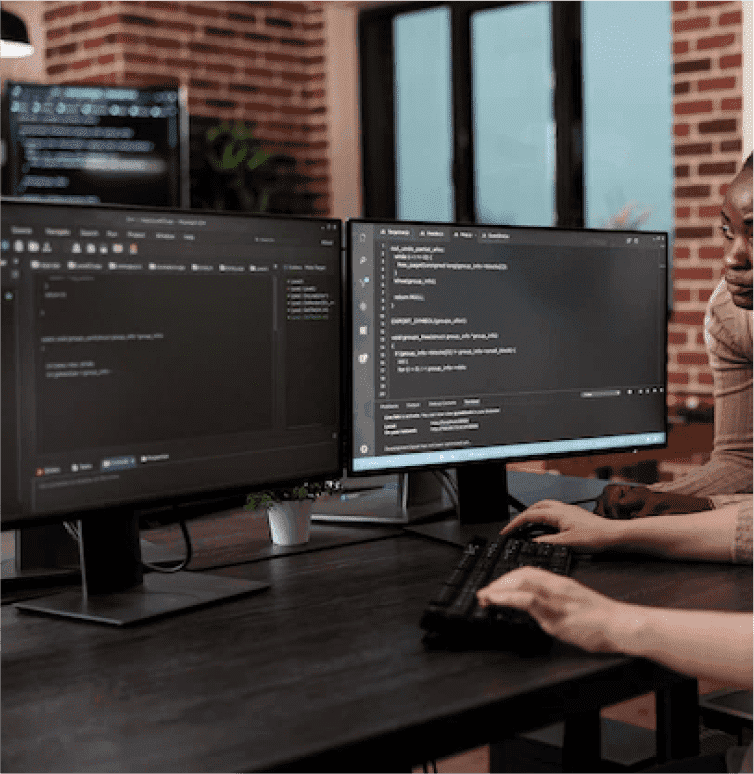
Cloud cost optimisation
Your cloud bill is bigger than your engineering salary. Here's the audit pass that fixes it.
Right-sizing instances. Reserved + savings plans where workloads are stable. Spot fleets for stateless workers. Autoscaling that actually scales down.
Average client savings: 30–40% on monthly cloud spend after the optimisation pass. Documented before/after.
- 01Instance right-sizing audit
- 02Reserved & savings plan strategy
- 03Spot fleet design
- 04Autoscaling tuning

Infrastructure migration
On-prem to cloud. Cloud to cloud. Bare metal to containers. The migration nobody wants to start.
We've done painful migrations — AWS to GCP, EC2 to EKS, monolith to microservices. None were one-shot weekend cutovers.
Phased migration. Traffic split. Rollback plans you can actually rollback to. Zero-downtime when the architecture allows it.
- 01Cloud-to-cloud migration
- 02On-prem → cloud lift
- 03VM → container refactor
- 04Monolith → service decomposition

From audit to autopilot.
Audit
Two-week deep-dive. We document what you have and what's wrong.
Plan
Prioritised roadmap. You see the order and the dates.
Build
Sprints. PR previews. You merge when you're ready.
Cutover
Phased traffic shift. Rollback ready. Zero-downtime where possible.
Handover
Runbooks, dashboards, on-call rota. Your team is trained.
Retainer
Optional. We stay on-call. Or we don't — the docs make us optional.
Reasons ops clients actually cite.
- 01Depth
Decade of production. The engineer on your call has run your kind of platform.
- 02IaC
Everything in code. Reviewed. Versioned. Replayable. No clicky-clicky disasters.
- 03Observability
Metrics, logs, traces wired before launch. Not patched after the first incident.
- 04Cost
30-40% average cloud bill reduction. We hand you a before/after spreadsheet.
- 05Honest scope
We tell you when K8s is overkill. We use Fly.io or ECS when it fits.
- 06On-call
Optional on-call retainer with documented runbooks. Or we hand off to your team.
- 07Security
SOC2, GDPR, HIPAA-ready patterns by default.
Infra for industries where downtime costs.
 Media
Media Fintech
Fintech Bank
Bank Startup
Startup Sport
Sport Agedcare
Agedcare Healthcare
Healthcare E-commerce
E-commerce Travel
Travel Education
Education Fitness
Fitness Real estate
Real estate Pharmaceutical
Pharmaceutical Retail
Retail Logistic
Logistic Industry 4.0
Industry 4.0
Our Recent Case Studies


Latest notes from the team.



Questions before the call.
What DevOps services do you offer?+
Architecture design, CI/CD pipelines, Kubernetes deployments, cloud cost optimisation, infrastructure migration, observability setup, on-call retainers. Pick the stages you need.
Which cloud providers do you cover?+
AWS, GCP, Azure, plus DigitalOcean, Fly.io, Hetzner for cost-conscious deployments. We pick what fits your workload, not what we used last quarter.
Do you do Kubernetes?+
Yes — when it's the right tool. We'll tell you when it's not (e.g. small monolith → Fly.io / ECS is simpler). We optimise for your team size, not our portfolio.
How long does an audit take?+
Two weeks for the audit + plan deliverable. Implementation timelines depend on scope — we'll give a real date.
Do you do on-call?+
Yes, as an optional retainer. We document runbooks so your team can take over whenever you want. We're not your hostage situation.
Got an infrastructure problem
to solve?
30-min call. We scope your problem, give you a fixed-price audit and a real timeline.
Ready to Kick-Off a New Project?
We are committed to providing our clients with the top solutions through global business ventures.
Trusted Clients

" They accepted a huge challenge and exceeded it. We're all better because they did. "
- Bill Crose Founder & CEO, Adyton
" The Leave and Attendance Management project has been a great value for our money. "
- GoPaL Prajapati Chief Project Manager, DB Corp Ltd (Dainik Bhaskar)
" Very Pleased with app development! highly recommended services! "
- Joey Wargachuk App Development
" Highly recommend for web development, apps, e-commerce, database management, etc. very reliable A+++ "
- Tony eCommerce site
" Avkash and his team at iTechNotion have done a great job developing our app and we are pleased enough to continue working with them to develop of our remaining applications. "
- Selwyn IOS app development
" Very good work again. I recommended this great professional and excellent provider. The communication is very good. Is my partner from Portugal and a member that i want in my team of www.toranjadesign.com my company. "
- Amvidigal Android TV Launcher App
" Hired team for few tasks in last 2-3 years. Prompt reply, top notch service and affordable quotes. They even went extra mile to deliver tasks which were not their responsibility. "